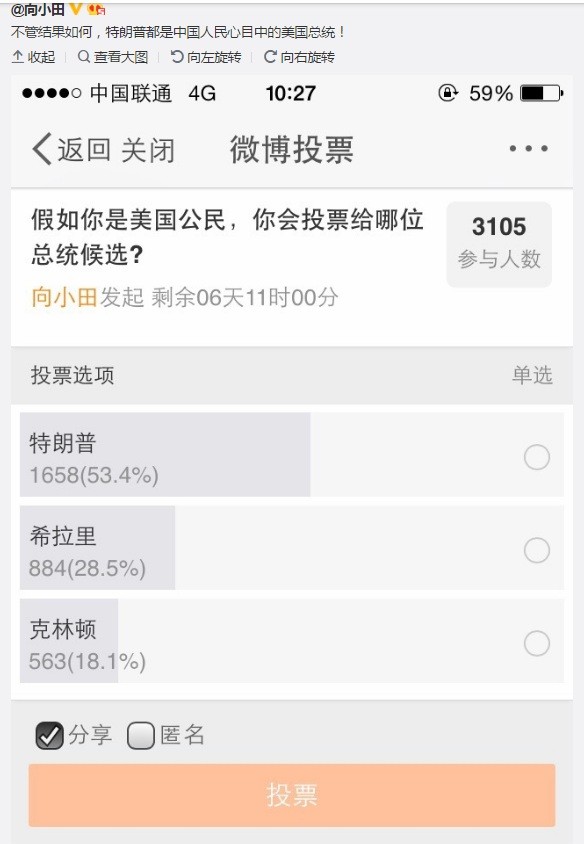
不过事实证明,微软的人工智能预测技术可能还不如印度人。
MogIA是印度人Sanjiv Rai开发的一个人工智能系统,你不会想到,早在2004年它就已经诞生了,对于一个依赖数据的产品来说,这是很大的优势。
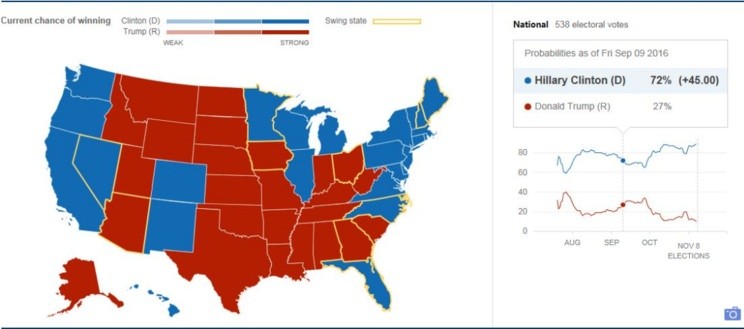
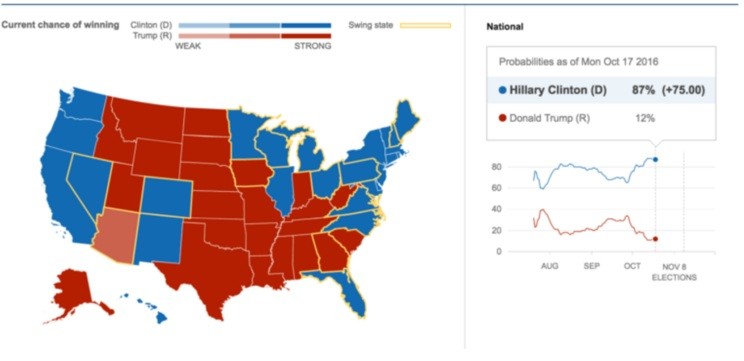
MogIA做出分析的来源很简单,就是来自Google、Facebook、Twitter以及YouTube这些网络平台上的2000多万个数据点。通过采集并分析这些数据,MogIA之前已经成功预测了民主党和共和党内部选举的结果。而在10月底,当公众民调都显示希拉里领先的时候,MogIA却认为特朗普会最终成为美国总统,结果它又一次证明了自己。
不过,Mog IA明显是一个更有利于特朗普的AI系统,它不会考虑它检测的用户活动的语气或意图,而是单纯地检查热度。因此,如果有人在Twitter上发表对Trump的负面态度,AI也将其简单地标注为「参与」,认为是积极的量度。这正应了特朗普所擅长的:任何宣传都可以是好的宣传。
但,每每谈及人工智能,我们都不得不想象一下我们的未来:当人工智能技术趋于成熟,它那么聪明,我们要不要干脆直接让它们帮我们投票算了?就像它能叫你起床,在你吃早餐的时候为你播放一首颇得你欢心的乐曲;然后你会坐着自己的自动驾驶汽车去公司上班,路上没事的时候可以看看一些AI已经帮你选好的新闻…
正如我们上面所说,人工智能能帮你做生活中的绝大多数事情,帮你选总统也不在话下。而这时,我们就要考虑一下了:在未来,你是否真的放心让机器算法替你选总统?
千万不要以为这只是一个不切实际的设想,事实上,只要收集到你之前表达过的意见和你所在州其他选民的意见数据,你的AI助手就能为你推荐一个选择,比如说民主党候选人XX。这时,你也许只需要点击一下屏幕上的「agree」就能让AI帮你投出这神圣的一票,让你不必非要在希拉里和特朗普两个你都不想选的人里面硬选一个。而这也许就是人们未来的生活。

之前,Tech Crunch就「算法选总统」这个很可能在未来困扰我们的大概率事件进行了分析。「人类在这个过程中该扮演何种角色?」、「算法帮我们选总统究竟靠不靠谱?」…结合这些分析,也许我们可以对四年之后的美国总统选举大戏更加期待了。
人类应该在AI时代扮演何种角色?
正如我们上面所说,在未来,「你也许只需要点击一下屏幕上的『agree』就能让AI帮你投出这神圣的一票」。然而,这其中还存在不少更深层的问题,比如说人类应该以何种身份存在其中?
事实上,从理论上说,只要有了足够多的数据,你的AI助手给你的建议比其他什么评论员和专家都更靠谱。但让人们把这样重要的公民义务交给机器来做还是难以接受的――即使机器可能才知道何种选择对你是最好的。
不过,我们往往会忘记,那种看似无形却又能自动做出推理的数学模型其实是由其他人根据我们的兴趣、地理位置、行为习惯、财产状况和健康情况等多种因素设计得出的。
当前关于算法文化的众多讨论都集中在人类在算法设计中所起的作用:算法设计者潜意识中的信念和偏见是否会被写进能影响我们做决定的算法当中。目前舆论界对此充满恐惧,人们担心开发者们会在编写算法时允许对某些人群的潜在歧视,更糟的是,技术平台会作为通过这些信息的看门人。就像John Mannes所说:「一个充满偏见的世界能产生偏见的数据,而偏见化的数据又会继续得到偏见化的AI框架。」
就像是上面提到过的由印度人Sanjiv Rai开发MogIA系统,它的算法就更有利于特朗普而非希拉里,这种情况下我们该如何信任人工智能?
「算法决定论」:我们塑造了我们的算法,然后它们再来塑造我们
但是,从另一个角度来说,推动上面这种论点的决策者和专家容易误解算法偏见的证据,他们常常责怪算法背后的人而不是算法本身。但事实上,算法的偏见很少源于人类开发者。在大多数情况下,它们都源于用于训练这种算法的数据,而这才是危险的真正来源。
让我们先把这些疑虑放一放,来回顾一下机器学习究竟是如何运作的。通过应用统计学习技术,研究人员可以开发能够自动识别数据中所存模式的计算模型。为了实现这一点,这个模型需要在大数据集上进行训练,通过这种训练来发现数据中的边界和关系。数据越多,准确度就越高。
在那些针对用户的个性化应用中,这些统计学习技术用于为用户创建一个算法上的「身份」,其中包括使用习惯、偏好、个性特征、社交结构等多个维度。然而,这种数字化身份不直接基于用户的自我感觉,他们的凭证是一群可测量数据点的集合以及机器给出的理论解释。
但是,AI只能根据历史数据对未来进行预测,这就是为什么通过过去的美国总统图像训练的神经网络预测唐纳德・特朗普会赢得这次选举,因为过去的美国总统都是男的,数据没办法推断性别是不是模型的相关特征。所以,如果我们使用这个AI来替我们投票,它肯定会投给特朗普。
然而,事实上,我们每个人在社会中的身份是动态的、复杂的,其中包含很多矛盾的因素。根据我们的社会背景,我们可能会有不同的行为,这就需要我们的AI助手在不同的场景下替我们做出不同的决策。
除了我们默认的自我介绍之外,我们有很多的原因想要去制定不同的身份和不同的群体进行差异化的互动。如果我们想要去尝试不同的社会角色和不同的身份选择,这会发生什么?就像美国论坛4chan的创始人Chris Poolea.k.a.moot所说:「个人的身份就像棱镜,人们会通过很多不同的视角来看你。」
区分这些不同的自我呈现并将它们映射到不同的社交环境中对于现有的被训练成单一身份的AI来说是一大挑战。有时候你可能会产生「我是谁?」的这个问题,但你的AI助手知道,因为它知道你过去是谁。
我们越依赖于日常生活中的个性化算法,它们将越能塑造我们看到的东西,我们读到的东西,我们谈论的人,以及我们的生活。因为通过持续关注我们的生活,新的推荐会从之前那些让我们开心的推荐内容上学习,然后推给我们相同的东西。
当你的过去决定了你的未来,再想要通过开放性和自发性寻求个人发展将变得更加困难。就像丘吉尔当年说过的那样,「算法决定论」的本质就是:我们塑造了我们的算法,然后它们再来塑造我们。
「坏」的AI将你带去「美丽新世界」
今天,各式AI应用已经在我们的生活中随处可见了。但还有两个主要的挑战阻挡我们达到我们在文章开头提到的场景。
从技术进步的角度来说,在不同应用程序之间的数据交换缺乏互通性标准,这阻止了AI的个性化发展。想要真正有用,现有的机器学习系统需要更大量的个人数据,而这些数据现在都在大公司的专有数据库中孤立存在。不过目前已经有一些大公司开始合作来做这件事,展望未来,这对于建立公众对这项技术的信任至关重要。
而从社会进步的角度来说,存在一种隐含的对快速发展的AI技术的厌恶情绪,人们似乎有些担心对AI助手们失去控制。同时,对AI技术的恐惧也被许多反乌托邦科幻小说中的情节所影响,里面描绘了拥有情感的「坏」AI接管世界的可怕场景。
然而,我们所向往的未来既不是《终结者》也不会是《1984》,它可能更接近于《美丽新世界》中的描绘的享乐社会:通过为人们提供普遍存在的幸福感和自我放纵的制度,技术控制了整个社会。
是时候为自己负责了
当然,虽然技术总是在前进,但希望永存。2016年全球青年社区年度调查显示,年轻人认为AI是未来主要的技术趋势。更重要的是,21%的受访者表示支持人形机器人的权利。年轻人们似乎对生活中的AI抱有一个越来越积极的态度。
在欧洲,欧盟新出台的《一般性数据保护法案》(GeneralDataProtectionRegulation)给了用户申请某项基于算法得出的结论的解释权,这可以限制极端形式的算法决定论。这项法案预计将会在2018年5月之前在全欧盟国家实施。但这是否会引起大公司算法上的变动还不得而知。
不过,现在是时候去找到一条明智的道路来创造透明和负责任的人工智能,以此改善人类的集体未来。因此,在跳跃到位置的未来之前,我们应该问问自己:我们究竟想要人类和AI之间的关系变成什么样子?重新思考这些问题能让我们设计出非确定性、透明和负责任的算法,这可能更有可能真正适应我们每个人复杂且不断变化的个性。






 发表于 2016-11-14 10:20:01
发表于 2016-11-14 10:20:01